Week1 classnotes
by Hasan
This is my class Note of courseara Specialisation of Machine learning in Production. This is the 2nd course of the specialization. This course is divided into four weeks. This is the class notes of week1
1. Introduction to Machine Learning Engineering in Production
Overview
- In Production ML it is assumed only 5% of the used as a code. Following figure square size may be approximation of ML code
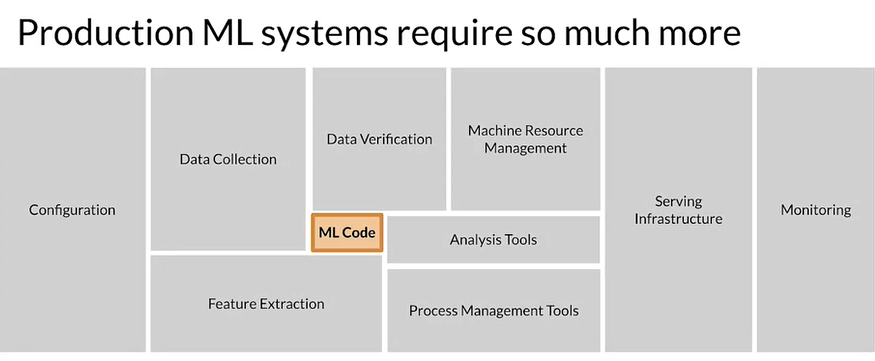
- difference between research ML and Production ML

So actually production ML is a mixture of Machine learning development + Modern Software development
Managing the entire life cycle of data
- Labeling
- Feature space coverage- training data set receives the same feature space as the model receives
- Minimal dimensionality- want to reduce the dimensionality of feature vector to have better system performance.
- Maximal predictive data- but during dimensionality reduction of feature vector also needs to consider to have the best performance of the model.
- Fairness- Fairness of data and model also needs to consider, specially
- Rare conditions - Rare condition. Health care, fraud detection needs to be consider, because in those application rare cases are extremely important.
Modern software development
Yes off course previous things are important, but you are putting a product into development, so you need to consider all the precaution which is necessary for a software deployment. So additionally following things need to be consider.
- Scalability: can it be both up and down scalable?
- Extensibility: If new things needs to be added, can you do it without problem?
- Configuration: Does it has well defined configuration?
- Consistency \& reproducibility: Is it consistent, is the result reproducible?
- Safety \& security: Is it hard to get attacked?
- Modularity:Is it modular, following modern software development principles?
- Testability:Individual unit can be tested, end to end test can be done?
- Monitoring: Continuously perform the health and performance of the system. If there is a problem, can it be alerted?
- Best practise: Is it following the industry best practises?
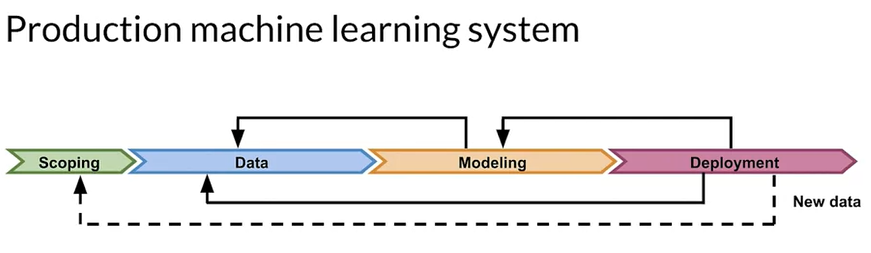
Production machine learning system
-
Scoping
- Define project and goal
- Resources
-
Data
- Define data and establish baseline
- label and Organize data
- Sometimes also require human label performance and baseline definition.
-
Modelling
- Select and train model
- Perform error analysis
-
Deployment
- Deploy in production
- Monitor and maintain system performance
We actually live a world where everything changes dramatically. So may be there will be time when degradation of your model performance will occur. So continuous monitor the model performance will help you to detect the deterioration of model. Then need to again go to Modelling part of the model.
- So may be this time you need to change the data.
- May be that can also affect the project design–> re scoping may also be necessary
- Following picture will be a great representative of a ML production life cycle
Challenges in production grade ML
- Building integrated ML systems
- Continuously operate in production
- Sometimes required 24/7
- Handle continuously changing data
- Optimize compute resource costs
ML Pipelines
Directed acyclic graphs
- A directed acyclic graph (DAG) is a directed graph that has no cycles
- ML pipeline workflows are usually DAGs, some advanced cases also in cycle
- DAGs define the sequencing of the tasks to be performed, based on their relationships and dependencies.
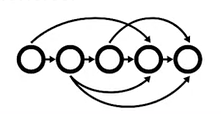
- The edges are directed but no cycle, that makes the DAGs a DAG.
Pipeline orchestration frameworks
- Responsible for scheduling various components in an ML pipeline DAG dependencies.
- Help pipeline automation.
- Some example Airflow, Argo, Celery, Luigi, Kubeflow
Tensorflow Extended (TFX)
- End-to-end platform for deploying production ML pipelines

- This sequence of components are designed for scalable, high-performance machine learning tasks
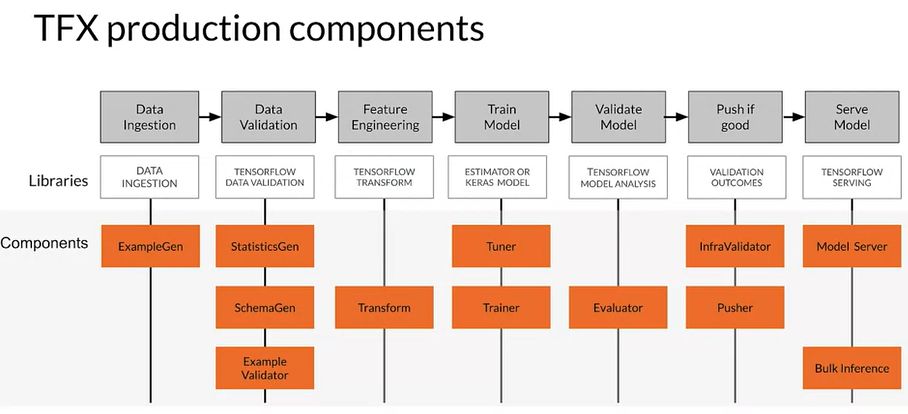
- TFX is built upon open source libraries like Tensorflow data validation, tensorflow transform
- The orange components use and leverage those libraries and form your DAGs
TFX Hello World
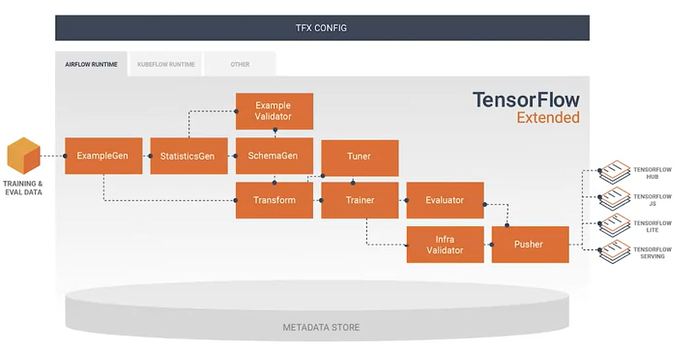
- ExampleGen
- StatisticsGen - ranges, categorical, types etc
- Example validator - look for problem in the data
- SchemaGen - Generate Schema for the data
- Transform - Feature Engineering
- Tuner, Trainer -Train the model and hyper parameters of the model
- Evaluator - Deep analysis of performance of the model
- Infra validator - We can run our model on the infrastructure we have(e.g. do we have enough memory)
- Pusher - Pusher push the model
- May be tensorflow hub for future transfer learning
- May be in tensorflowjs, if we want to use our model in a web browser.
- Maybe push in tensorflowlite for mobile application
- Or push in tensorflow serving and use our model on a server or on a serving cluster.
2. Collecting Data
Importance of Data
-
Normally in real world it is difficult to get data, sometimes it is expensive(not only because of money but only money or data collection tool)
-
Uber says: Data is the hardest part ML and the most important piece to get right… Broken data is the most common cause problems in production ML systems
-
Gojek says: No other activity in the machine learning life cycle has a higher return on investment than improving the data a model has access to.
ML: Data is a first class citizen
-
In software engineering first class citizen in a programming language is an entity which supports all the operations generally available to other entities, and ML data is a first class citizen.
-
Software 1.0
- Explicit instruction to the computer
-
Software 2.0
- Specify some goal on the behaviour of a program
- Find solution using optimization techniques
- Good data is key for success
- Code in Software = Data in ML
Everything starts with data
- Garbage in garbage out
- Models are not magic
- Meaningful data
- maximize predictive content
- remove non-informative data
- feature space-coverage
Data Pipeline
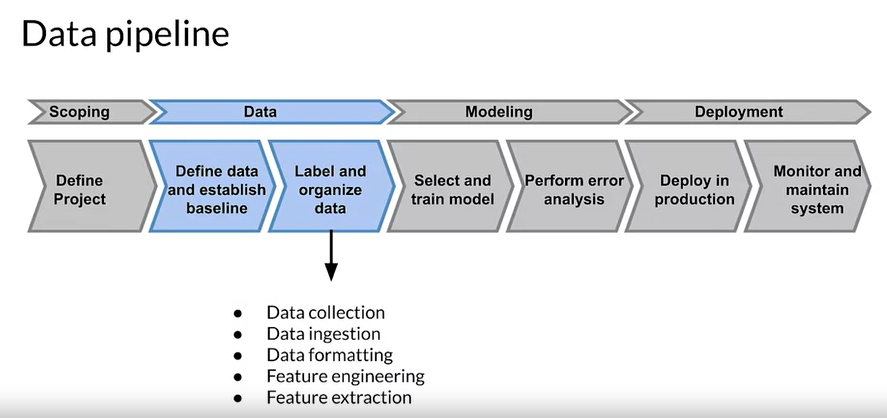
Data Collection and Monitoring
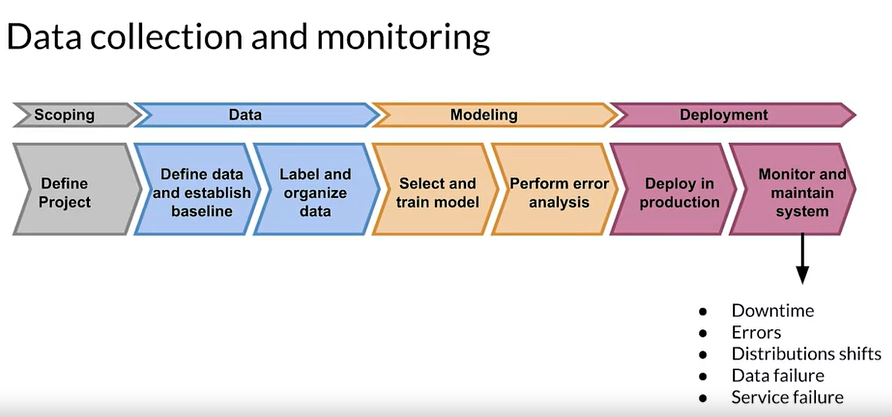
Key points
- Understand users, translate user needs into data problems
- Ensure data coverage and high predictive signal
- Source, store and monitor quality data responsibility(not only getting data but whole life cycle data monitoring is needed)
Example Application:Suggesting Runs
- We are talking an application where it will suggest runs to the runners based on fitness level or other things.
- First step is to understand the users.
- Users- Runners
- Users Need - Run more often
- Users Actions - Complete run using the app
- ML System output - What routes to suggest - When to suggest them
- ML System learning - Patterns of behaviour around accepting run prompts - Completing runs - Improving consistency
Key considerations
- Data availability and collection
- What kind of data/ how much data is available?
- How often does it need to new data come in ?
- Is is annotated ?
- If not, how hard/expensive is it to get it labeled?
- Translate user needs to data needs
- Data needed
- Feature needed
- Labels needed
- Here is an example of data
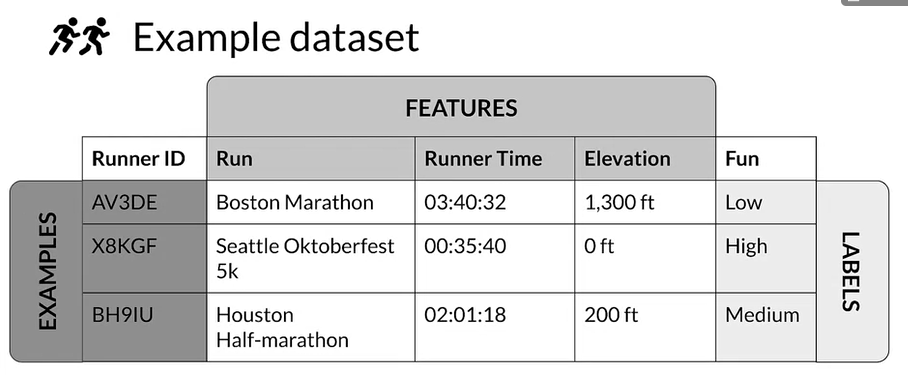
- labels are here Fun, how the users rate this
Get to know your data
- Identify data sources
- Not the first time but an ongoing basis
- So not only training but also the data when doing inference
- Check if they are refreshed
- Consistency for values, units, \& data types
- Monitor outliers and errors
Dataset issues
- Inconsistent formatting
- Is zero “0”, “0.0” or an indicator of a missing measurement.
- Compounding errors from other ML Models
- If it is Ensemble
- Monitor data sources for system issues and outages
Measure data effectiveness
- Intuition about data value can be misleading.
- Which features have predictive values and what ones do not?
- Feature engineering helps maximizing the predictive signals.
- Feature selection helps to measure the predictive signals.
Translate user needs into data needs
- Data Needed
- Running data from the app
- Demographic data
- Local geographic data
- Features Needed
- Runner Demographic
- Time of day
- Run completion rate
- Pace
- Distance run
- Elevation gained
- Heart rate
- Labels Needed
- Runner acceptance or rejection of app suggestions
- User generated feedback regarding why suggestions were rejected
- Need to think how to get those feedback so that you can use them in future to train your model
- User rating or enjoyment of recommended runs
Key points
- Understand your user, translate their needs into data problems
- What kind of/ how much data is available
- What are the details and issues of your data
- What are your predictive features
- What are the labels you are tracking
- What are your metrics
Responsible Data: Security, Privacy, \& Fairness
Outline
- Data Sourcing
- Data Security and user Privacy
- Bias and Fairness (labeling bias removal)

- Open source images, left is pretty correct but on the right it is somewhat incorrect, so it is people but also marriage ceremony, this is classic example of bias in label
- Normally there are different sources of dataset
- Web scraping
- Open-source dataset
- Build synthetic dataset
- Build your own dataset
- Collect live data
Data security and privacy
- Data collection is not just your model
- Give user control of what data can be collected
- Is there a risk of inadvertently revealing user data?
- Compliance with regulation and policies (e.g. GDPR)
User privacy
- Protect personally identifiable information
- Aggregation- replace unique values with summary values
- Redaction -remove some data to create less complete picture
ML systems can fail users
- Representation harm
- fail a particular type of user creating bias against them
- Opportunity denial
- Real life opportunity impact ( not give loan )
- Dis appropriate product failure
- Skewed output (Sometimes in case of white people in face recognition found in research)
- Harm by disadvantage
Commit to fairness
- Make sure your models are fair
- Group fairness, equal accuracy
- Bias in human labeled and/or collected data
- ML models can amplify biases
Reducing bias: Design fair labeling systems
- Accurate labels are necessary for supervised learning
- labeling can be done by:
- Automation (logging or weak supervision)
- Humans (aka “Raters”, often semi-supervised)
Types of human raters
- Human who labels data are raters, but who are those raters
- Generalist (Crowd sourcing tools)
- Subject matter experts (Specialized tools e.g. medical image)
- Your users (Derived labels e.g. tagging photos)
Key points
- Ensure rater pool diversity
- Investigate rater context and incentives
- Evaluate rater tools ( how rater use those tools, whether standard rules are used)
- Manage cost (Need to understand and take account the cost of labeling)
- Determine freshness requirements (when to refresh data)
3. Labelling data
Case Study: Degraded Model Performance
- The only constant thing in the world is change (said in 500 B.C. still true)
- For example there is a retailer who sells shoe and try to model click-through-rate(CTR) helps him decide how much inventory to order
- Suddenly the AUC prediction accuracy degraded for a particular items (men dress shoe)
- Why ?
- How do even know even there is a problem for men shoe
- Your model is running and giving prediction. So if good practises is not used for production, then may be this retailer will find too many shoes or not enough shoes.
- So in business people don’t want this, because that cost money
Case study: taking action
- Need to think how to detect such problems early ?
- What the possible causes are ?
- Try to put systems in play to solve them
What causes Problems ?
- Kind of problems
- Slow - example:drift
- Fast - example:bad sensors, bad software update
Gradual Problems
- Normally they are interrelated, it is difficult to make a hard line between them
- Data changes
- Trend and seasonality (changes of data or change of world difficult to differ)
- Distribution of feature changes
- Relative importance of feature changes
- World changes
- Style changes
- Scope and processes change
- Competitors change
- Business expands to other goes
Sudden Problems
- Data Collection Problem
- Bad sensor/camera
- Bad log data
-
Moved or disabled sensors/cameras
- System problems
- Bad software update
- Loss of network connectivity (Sometimes network can also go down)
- System down (System can also go down)
- Bad credentials
Why “Understand” the model
- Misprediction don’t have uniform case to your business
- Some has little effect
- Some has huge effect
- The data you have and data you wish you had
- Sometimes lots of noise (Sensor data from WiFi)
- The model objective is nearly always a proxy for your business objectives
- Some percentage of your customers may have a bad experience
- As a business owner you may be need those number as much as possible
- May be you try to understand what customers that would be, so that you can design your experiment
Data and Concept Change in Production ML
Outline
- Detecting problems with deployed models
- Data and concept change
- Changing ground truth
- Easy problems
- Harder problems
- Really harder problems
Detecting problems with deployed models
- Data and scope changes
- Monitor models and validate data to find problems early
- Changing ground truth: label new training data
Easy problems
- Ground truth changes slowly (months, years)
- Model retraining driven by:
- Model improvements, better data
- Changes in software and/or systems
- Labeling
- Curated datasets
- Crowd-based
Harder problems
- Ground truth changes faster (weeks) e.g. styles of shoes
- Model retraining driven by:
- Declining model performance
- Model improvements, better data
- Changes in software and/or systems
- labeling
- Direct feedback
- Crowd-based
Really Hard problems
- Ground truth changes very fast (days, hours, min)
- Model retraining driven by:
- Decline model performance
- Model improvements, better data
- Changes in software and/or systems
- Labeling
- Direct feedback
- Weak supervision
Key points
- Model performance decays over time
- Data and concept drift
- Model retraining helps to improve performance
- Data labeling for changing ground truth and scare labels
Process Feedback and Human Labeling
Data Labeling
- Variety of Methods
- Process Feedback (Direct labeling)
- Human Labeling
- Semi-Supervised Labelling (label part of dataset)
- Active Learning (Most important of data labeling)
- Weak Supervision
- In this module we will be discussing only first two process
- Process Feedback (Actual vs predicted click-through)
- Human Labeling (Example: Cardiologists labeling MRI Images)
Why is labeling important in production ML?
- Using business/organisation available data (for supervised learning label is necessary, however without labeling we can not use them perfectly. Yes sure unsupervised learning can be applied)
- Frequent model retraining
- Labeling ongoing and critical process (Sometimes monthly, weekly or daily)
- Creating a training datasets require labels
Direct labelling: continuous creation of training of training dataset
- Features from inference requests
- Labels from monitoring predictions
- Join the results from monitoring system with inference requests
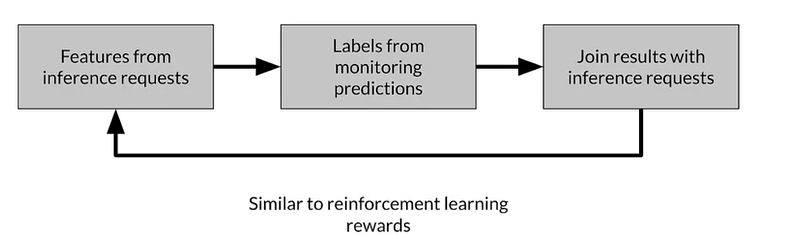
Process feedback -advantages
- Training dataset continuous creation
- Labels evolve quickly
- Capture strong label signals
Process feedback -disadvantages
- Hindered by inherent nature of the problem (Sometimes not possible)
- Failure to capture the ground truth
- Largely bespoke design
Process feedback- Open-Source log analysis tools
- Logstash
- Fluentd
Process feedback- Cloud log analytics
- Google cloud logging
- AWS ElasticSearch (not purely a log analysis tools, but log analysis can be done)
- Azure Monitor
Human Labeling
- People (raters) to examine data and assign labels manually
- Raw data
- Unlabeled and ambiguous data is sent to raters for annotation
- Training data is ready for use
Human Labeling Methodology
- Unlabeled data is collected
- Haman raters are recruited
- Instruction to guide raters are created
- Data is divided and assigned to raters
- Labels are collected and conflicts resolved
Human labeling- advantages
- More labels
- Pure supervised learning
Disadvantages
- Quality problem, different people can have different opinion (Radiologist)
- Slow
- Expensive
- Small dataset curation
Key points
- Various methods of data labeling
- Process feedback
- Human labeling
- Advantages and disadvantages of both
4. Validating Data
Detecting Data issues
Outline
- Data issues
- Drift and skew
- Data and concept Drift
- Schema skew
- Distribution skew
- Drift and skew
- Detecting data issues
Drift and skew
- Drift
- Changes in data over time, such as data collected once a day
- Skew
- Difference between two static versions, or different sources, such as training set and serving set
- Normally model decay occurs due to data drift
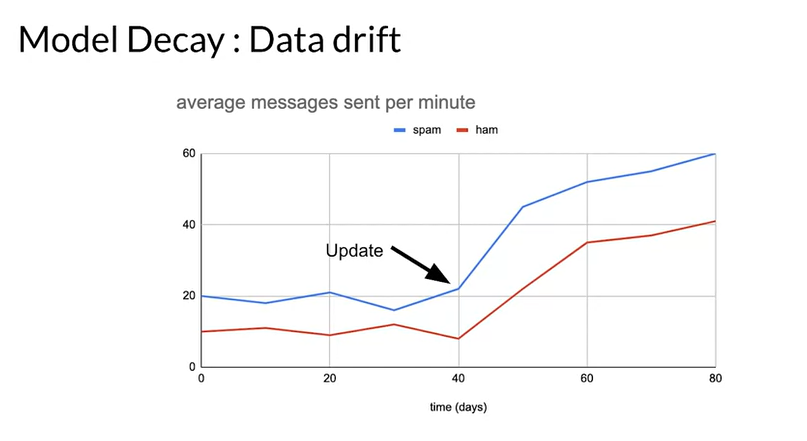
-
Here after software update spammers and non spammers both sending more messages.
-
concept drift when there is change in labels
Detecting data issues
- Detecting schema skew
- Training and serving data don’t conform to the same schema (float, integer or other thing)
- Detecting distribution skew
- Dataset shift –> covariate or concept shift
- Requires continuous evaluation
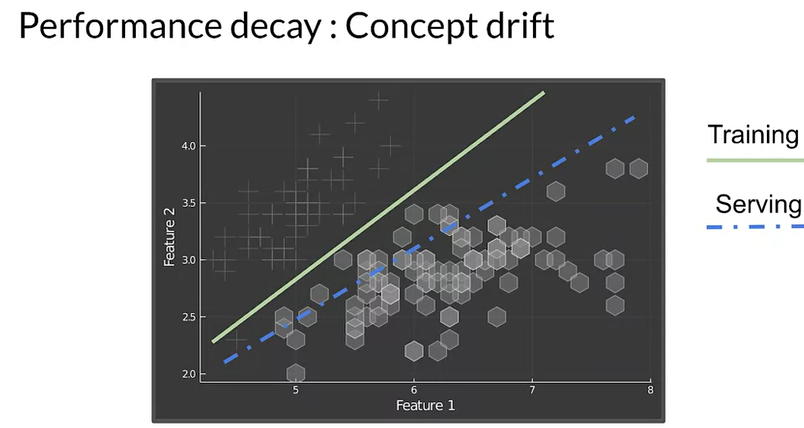
Detecting distribution skew
- Dataset shift
- x and y are not same during training and serving
- Covariate shift
- x shift in train and serving data
- Concept shift
- y change

Skew detection workflow
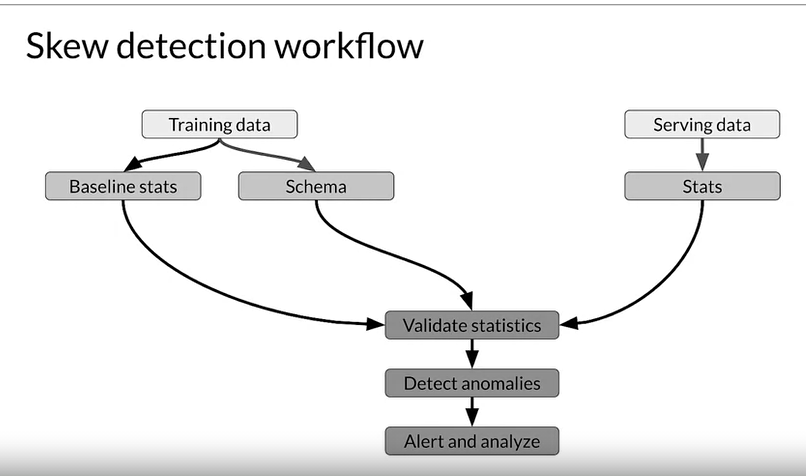
Tensorflow Data Valiadation (TFDV)
Please see this tutorial
tags: