im_path = Path(Path.cwd().parent/'data/patch_images')
msk_path = Path(Path.cwd().parent/'data/patch_masks')
im_path_tst = Path(Path.cwd().parent/'data/test_patch_images')
msk_path_tst = Path(Path.cwd().parent/'data/test_patch_masks')Dataset Preparation
datset preparation
get_dataset
get_dataset (im_path:Union[pathlib.Path,str], msk_path:Union[pathlib.Path,str])
Create a dataset from image and mask path
Dataset from own computer
#test_dataset = get_dataset(
#im_path_tst,
#msk_path_tst,
#)
#test_dataset image has 1725 images
masks has 1725 imagesDataset({
features: ['image', 'label'],
num_rows: 1725
})#dataset = get_dataset(
#im_path,
#msk_path
#)
#dataset image has 1642 images
masks has 1642 imagesDataset({
features: ['image', 'label'],
num_rows: 1642
})#test_eq(len(test_dataset['image']), len(test_dataset['label']))#test_eq(len(dataset['image']), len(dataset['label']))#dataset_dict=DatasetDict({'train':dataset, 'test':test_dataset})#test_dataset.to_parquet(Path.cwd().parent/'data/test_patch_dataset.parquet')84715121show_dataset
show_dataset (dataset)
#show_dataset(dataset) dataset index will be visualized: 224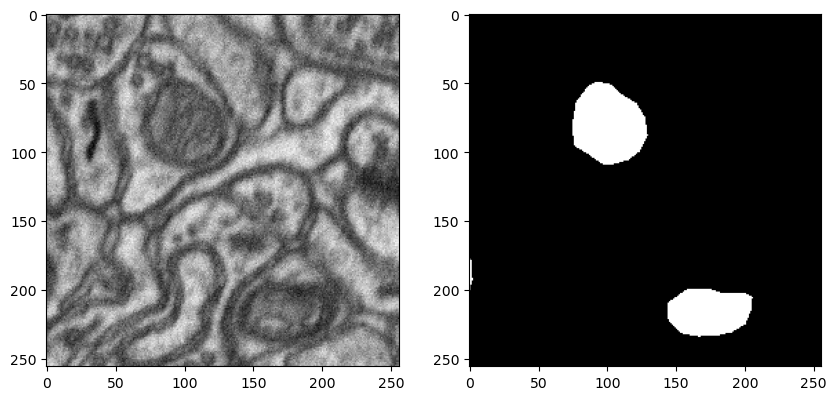
In case of download data from huggingface
from datasets import load_dataset
dataset = load_dataset("hasangoni/Electron_microscopy_dataset")Downloading readme: 0%| | 0.00/608 [00:00<?, ?B/s]Downloading readme: 100%|##########| 608/608 [00:00<00:00, 4.37MB/s]
Downloading data: 0%| | 0.00/80.6M [00:00<?, ?B/s]
Downloading data: 13%|#3 | 10.5M/80.6M [00:00<00:02, 29.9MB/s]
Downloading data: 26%|##6 | 21.0M/80.6M [00:00<00:01, 51.0MB/s]
Downloading data: 39%|###9 | 31.5M/80.6M [00:00<00:00, 53.1MB/s]
Downloading data: 52%|#####2 | 41.9M/80.6M [00:00<00:00, 56.4MB/s]
Downloading data: 65%|######5 | 52.4M/80.6M [00:00<00:00, 63.8MB/s]
Downloading data: 91%|#########1| 73.4M/80.6M [00:01<00:00, 65.1MB/s]
Downloading data: 100%|##########| 80.6M/80.6M [00:01<00:00, 66.0MB/s]Downloading data: 100%|##########| 80.6M/80.6M [00:01<00:00, 58.6MB/s]
Downloading data: 0%| | 0.00/84.6M [00:00<?, ?B/s]
Downloading data: 12%|#2 | 10.5M/84.6M [00:00<00:01, 42.9MB/s]
Downloading data: 25%|##4 | 21.0M/84.6M [00:00<00:01, 52.1MB/s]
Downloading data: 50%|####9 | 41.9M/84.6M [00:00<00:00, 75.4MB/s]
Downloading data: 62%|######1 | 52.4M/84.6M [00:01<00:00, 48.9MB/s]
Downloading data: 74%|#######4 | 62.9M/84.6M [00:01<00:00, 51.8MB/s]
Downloading data: 87%|########6 | 73.4M/84.6M [00:01<00:00, 53.4MB/s]
Downloading data: 99%|#########9| 83.9M/84.6M [00:01<00:00, 45.7MB/s]Downloading data: 100%|##########| 84.6M/84.6M [00:01<00:00, 49.1MB/s]
Generating train split: 0%| | 0/1642 [00:00<?, ? examples/s]Generating train split: 100%|##########| 1642/1642 [00:00<00:00, 12469.15 examples/s]Generating train split: 100%|##########| 1642/1642 [00:00<00:00, 12402.03 examples/s]
Generating test split: 0%| | 0/1725 [00:00<?, ? examples/s]Generating test split: 100%|##########| 1725/1725 [00:00<00:00, 12490.33 examples/s]Generating test split: 100%|##########| 1725/1725 [00:00<00:00, 12385.07 examples/s]datasetDatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 1642
})
})def show_hf_dataset(
dataset:Dataset,
idx:Union[int, None]=None,
split:str='train'
):
"Show hugging face random index"
if idx is None:
idx = np.random.randint(0, len(dataset[split]))
print(f' dataset index will be visualized: {idx}')
im_ = dataset[split]['image'][idx]
msk_ = dataset[split]['label'][idx]
fig, ax = plt.subplots(
1, 2, figsize=(10, 5)
)
ax[0].imshow(im_)
ax[1].imshow(msk_)show_hf_dataset(dataset) dataset index will be visualized: 189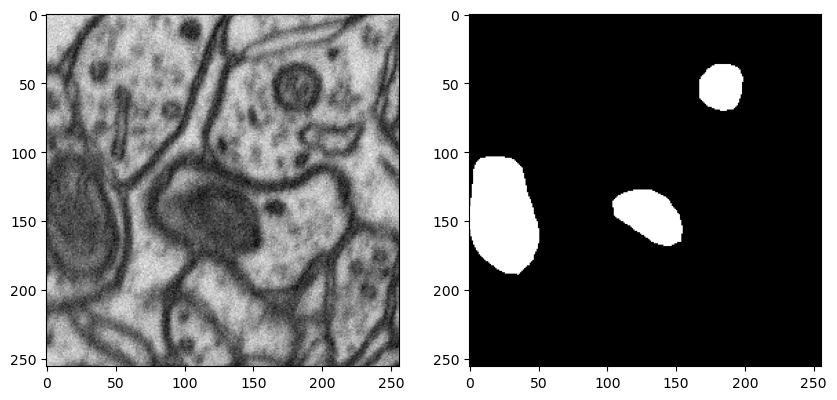
get_bounding_box
get_bounding_box (ground_truth_map)
- Careful here to make difference between torch Dataset and datsets.Dataset
SAMDataset
SAMDataset (dataset, processors)
Creating dataset for SAM training
train_ds = SAMDataset(
dataset=dataset,
processors=processor)#example = train_ds[0]
#for k,v in example.items():
#print(f'{k}: {v.shape}')(256, 256) <class 'numpy.ndarray'>
pixel_values: torch.Size([3, 1024, 1024])
original_sizes: torch.Size([2])
reshaped_input_sizes: torch.Size([2])
input_boxes: torch.Size([1, 4])
ground_truth_mask: (256, 256)#train_dl = DataLoader(
#train_ds,
#batch_size=2,
#shuffle=True
#)#batch = next(iter(train_dl))
#for k,v in batch.items():
#print(k,v.shape)(256, 256) <class 'numpy.ndarray'>
(256, 256) <class 'numpy.ndarray'>
pixel_values torch.Size([2, 3, 1024, 1024])
original_sizes torch.Size([2, 2])
reshaped_input_sizes torch.Size([2, 2])
input_boxes torch.Size([2, 1, 4])
ground_truth_mask torch.Size([2, 256, 256])